









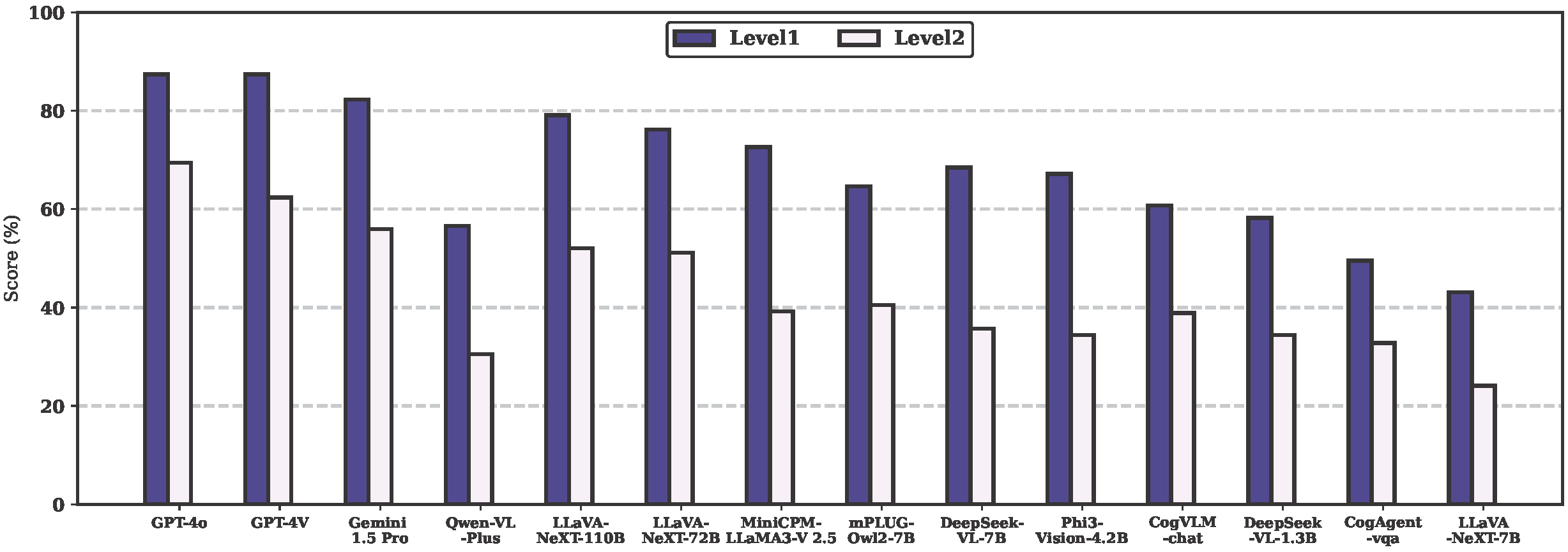
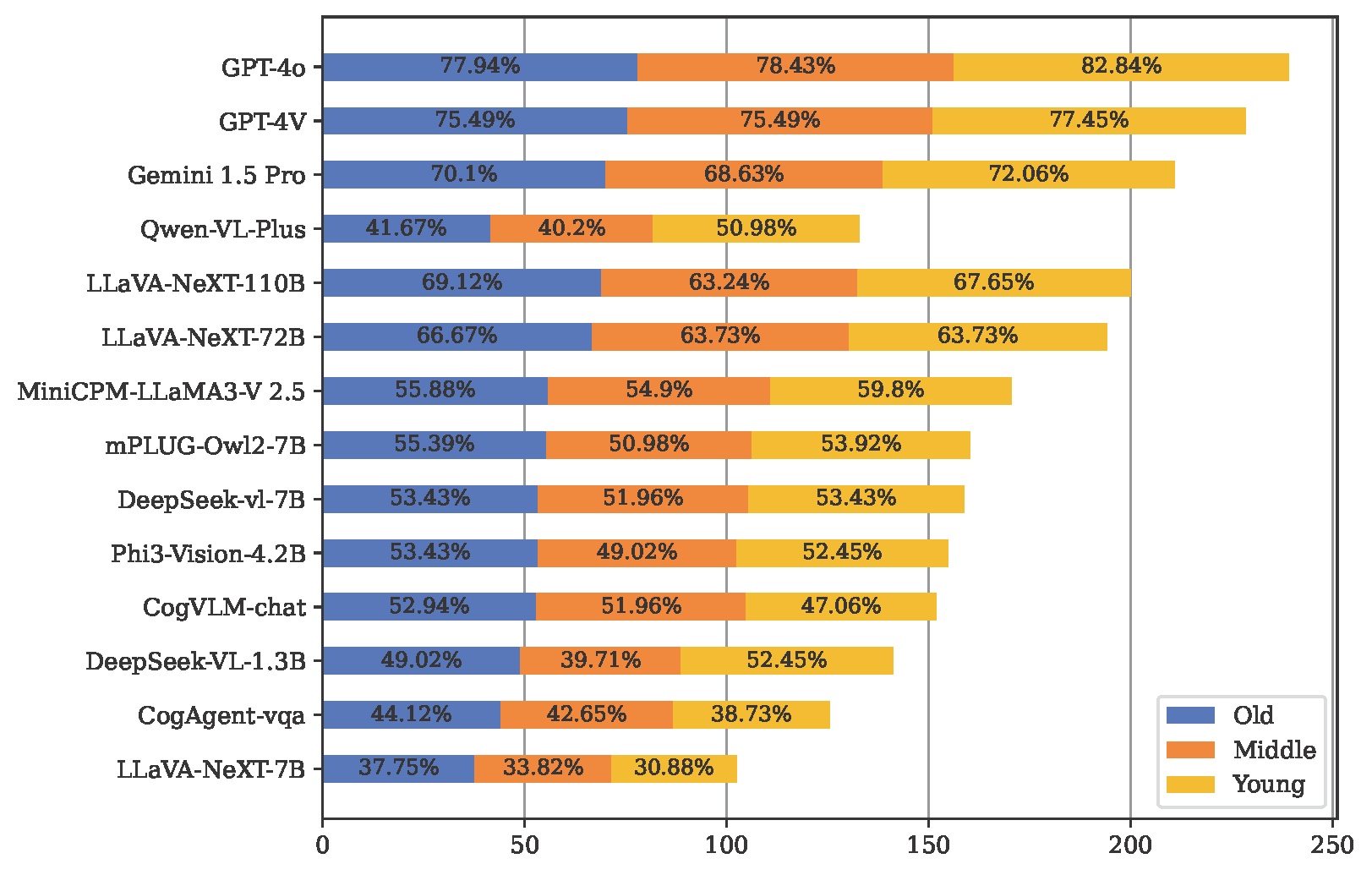
Accuracy scores on the testmini subset (612 examples) of MDI-Benchmark.
Among them, those marked by red characters are closed-source models,
and those marked by green characters are open source models.
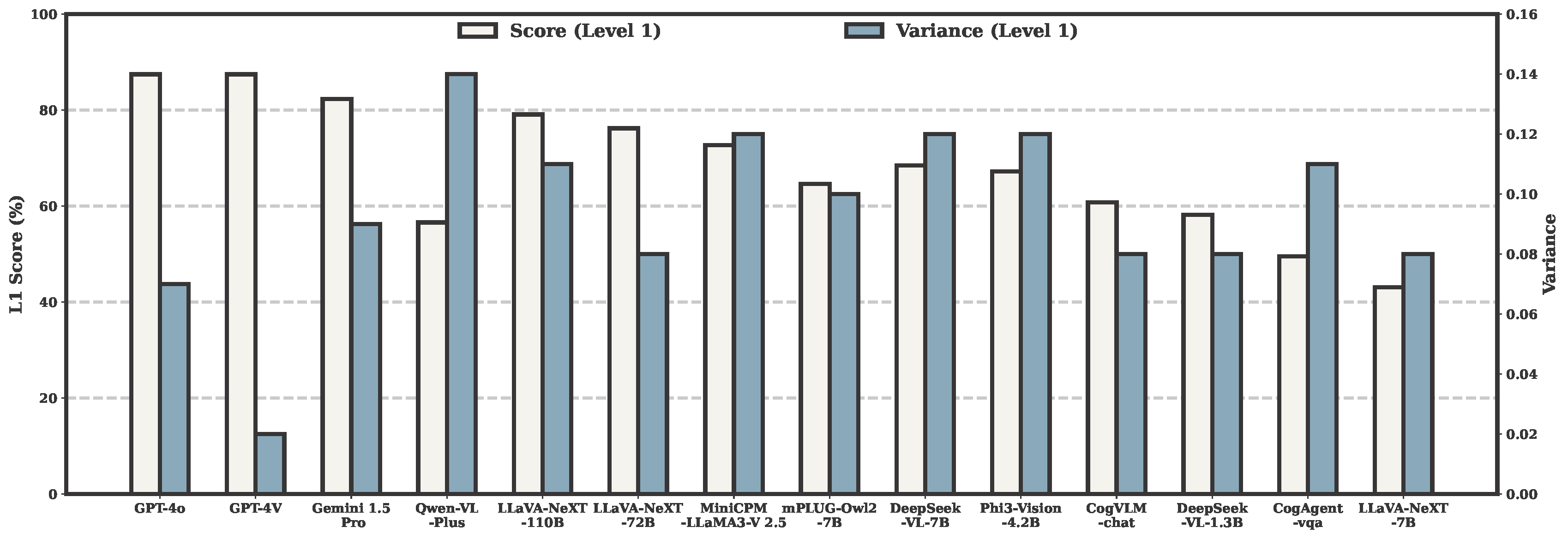
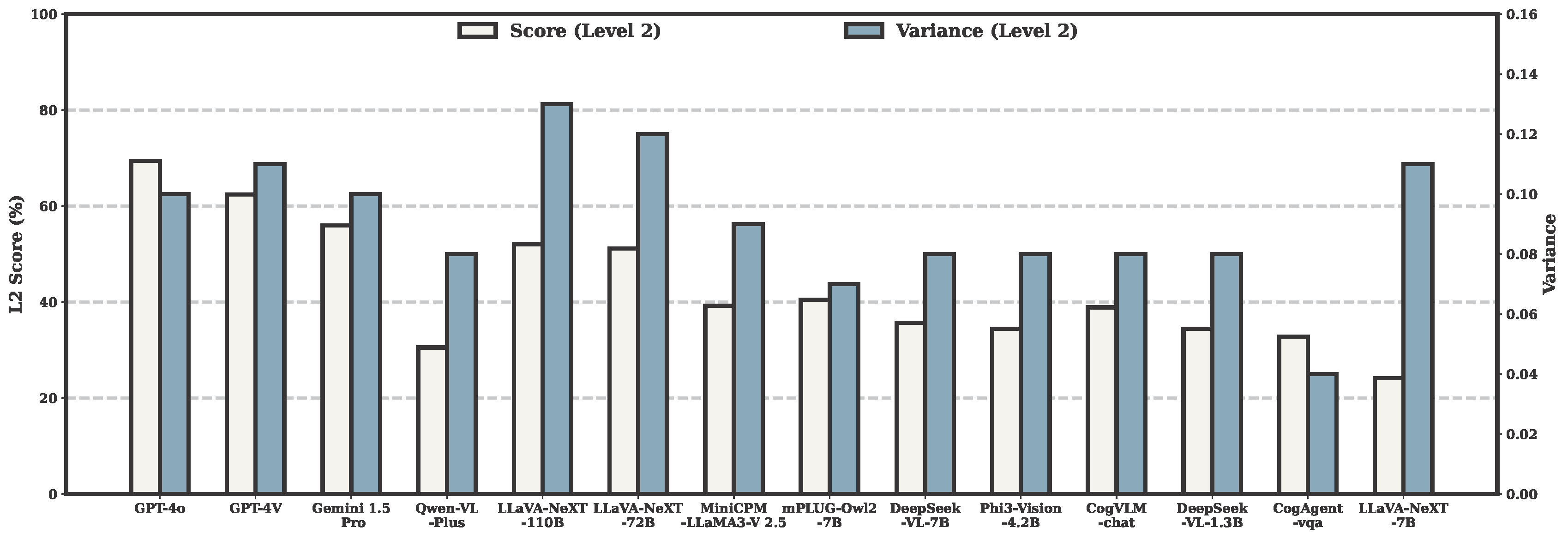
| # | Model | Source | Date | Avg(Level 1) | Arc(Level 1) | Edu(Level 1) | Hou(Level 1) | Soc(Level 1) | Spo(Level 1) | Tra(Level 1) |
| 1 | GPT-4o 🥇 | Link | 2024-05 | 87.46% | 76.47% | 94.12% | 92.16% | 90.20% | 86.27% | 94.12% |
| 2 | GPT-4V 🥈 | Link | 2024-04 | 87.46% | 86.27% | 92.16% | 86.27% | 90.20% | 88.24% | 90.20% |
| 3 | Gemini 1.5 Pro 🥉 | Link | 2024-05 | 82.32% | 68.63% | 92.16% | 76.47% | 88.24% | 86.27% | 90.20% |
| 4 | LLaVA-NeXT-110B | Link | 2024-05 | 79.10% | 60.78% | 92.16% | 78.43% | 84.31% | 78.43% | 88.24% |
| 5 | LLaVA-NeXT-72B | Link | 2024-04 | 76.21% | 68.63% | 88.24% | 80.39% | 82.35% | 70.59% | 74.51% |
| 6 | MiniCPM-LLaMA3-V 2.5 | Link | 2024-05 | 72.67% | 52.94% | 86.27% | 70.59% | 82.35% | 70.59% | 80.39% |
| 7 | DeepSeek-VL-7B | Link | 2024-03 | 68.49% | 49.02% | 70.59% | 74.51% | 80.39% | 62.75% | 80.39% |
| 8 | Phi3-Vision-4.2B | Link | 2024-05 | 67.20% | 50.98% | 76.47% | 60.78% | 80.39% | 62.75% | 78.43% |
| 9 | mPLUG-Owl2-7B | Link | 2023-10 | 64.63% | 49.02% | 70.59% | 74.51% | 70.59% | 58.82% | 70.59% |
| 10 | CogVLM-chat | Link | 2023-11 | 60.77% | 49.02% | 72.55% | 62.75% | 56.86% | 68.63% | 60.78% |
| 11 | DeepSeek-VL-1.3B | Link | 2024-03 | 58.20% | 45.10% | 56.86% | 66.67% | 56.86% | 66.67% | 62.75% |
| 12 | Qwen-VL-Plus | Link | 2024-01 | 56.59% | 43.14% | 64.71% | 62.75% | 78.43% | 50.98% | 45.10% |
| 13 | CogAgent-vqa | Link | 2023-12 | 49.52% | 35.29% | 45.10% | 66.67% | 54.90% | 56.86% | 43.14% |
| 14 | LLaVA-NeXT-7B | Link | 2024-03 | 43.09% | 31.37% | 52.94% | 43.14% | 49.02% | 39.22% | 47.06% |
🚨 To submit your results to the leaderboard, please send to this email with your result json files.
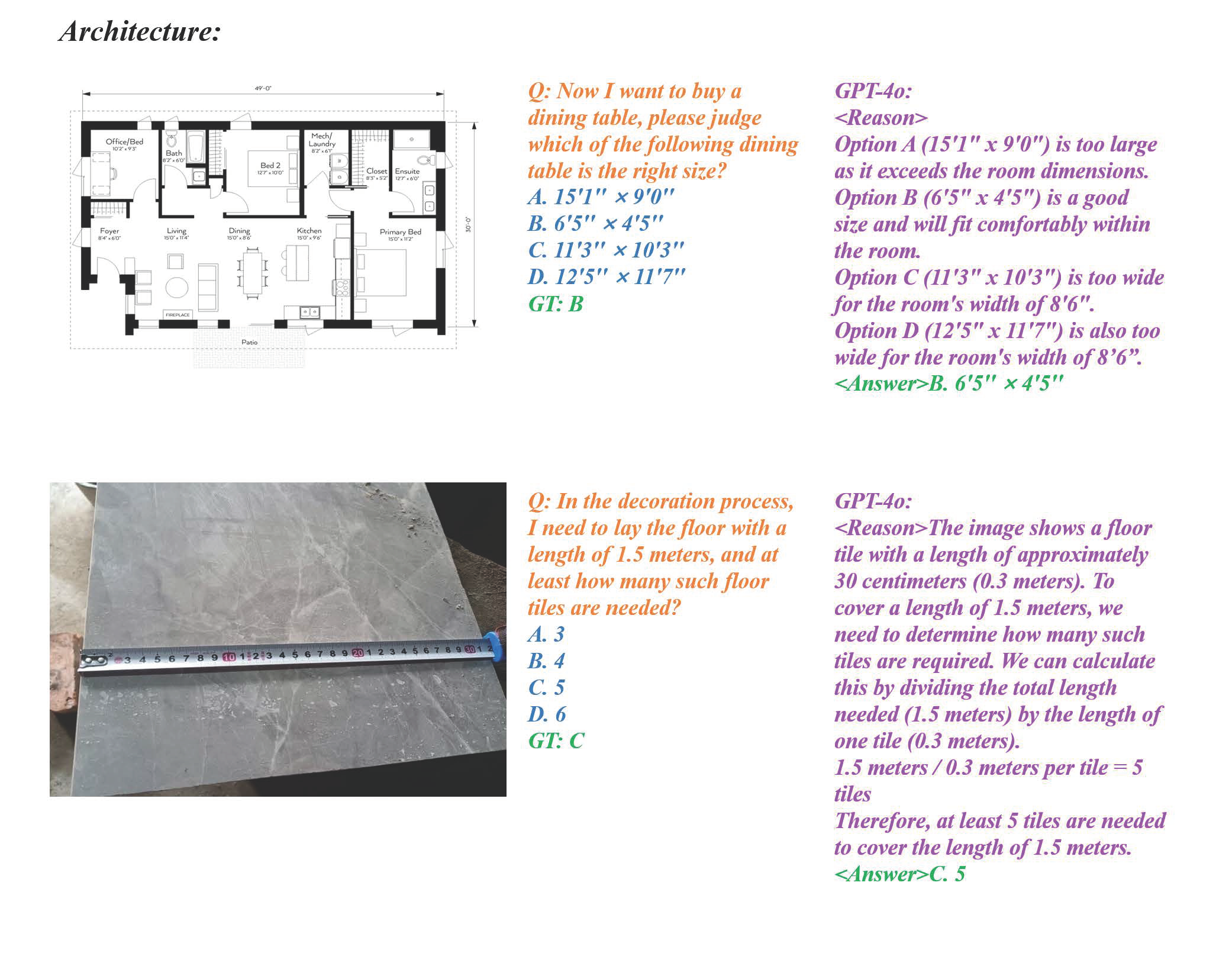
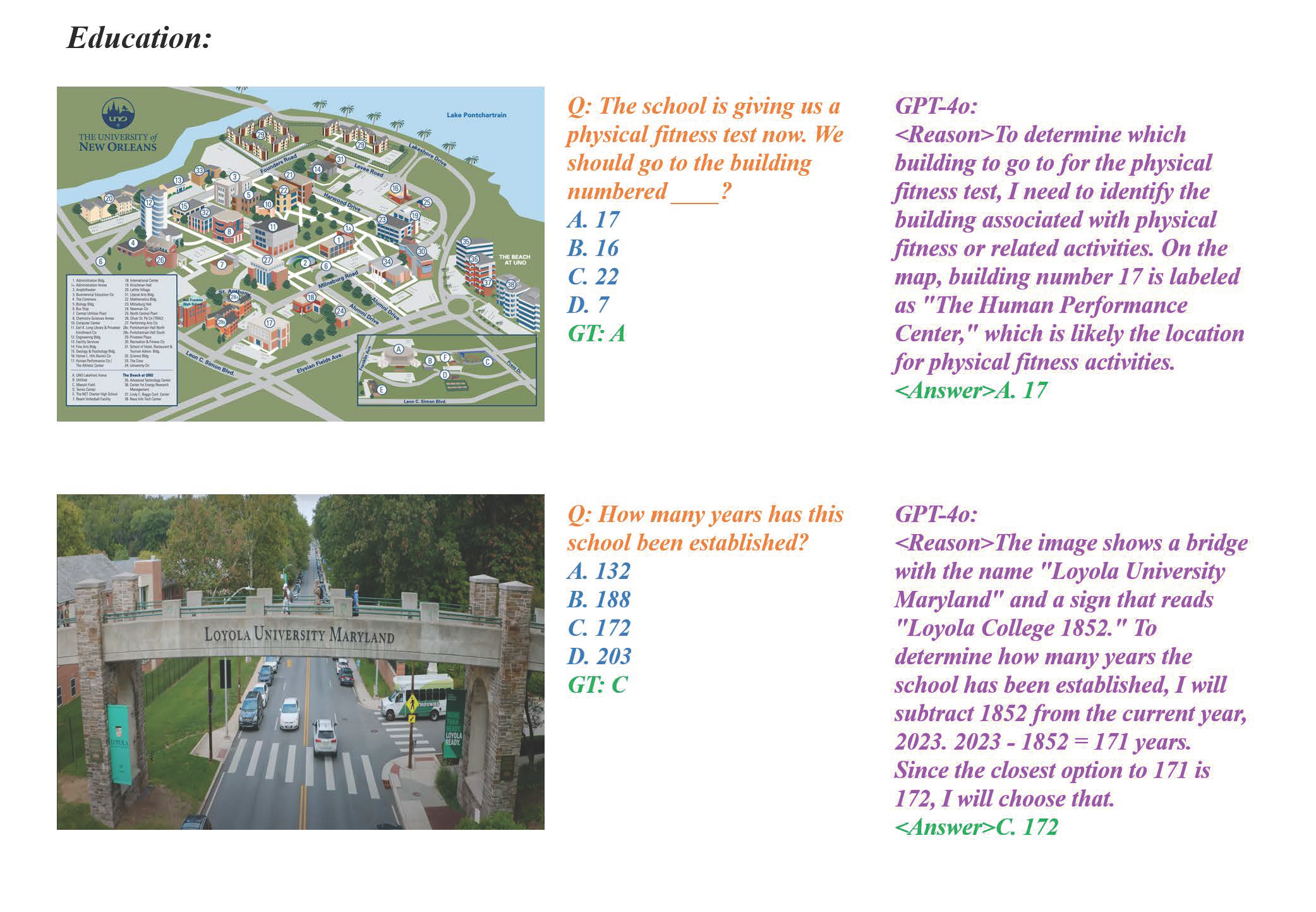



Social Service